
Introduction: What is GEMM?
Let’s first define what a GEMM is and why it is relevant in today’s world. GEMM refers to General Matrix Multiplication, a linear algebra operation that can be defined as:
$$ C = \alpha AB + \beta C $$
Where A, B and C are matrices and alpha and beta are scalars. Most of the time the part we will focus on will be just A and B since multiplying two matrices is the biggest challenge.
Without getting into too much detail, GEMMs are the backbone of modern AI, every model you run has lots of GEMMs behind, not just LLMs but vision models or classification models too. In this article we won’t cover why those neural nets are just a bunch of GEMMs (and some other things), the idea to grasp is that a good GEMM kernel means improvement in the AI world.
By the way, the word kernel might sound strange to you, we are not talking about anything Linux related. Kernel is the name we use to describe a highly specialized software function or subroutine in charge of performing an operation. In this article we will be developing GEMM kernels for the CPU.
Why the CPU?
Today’s AI world is clearly dominated by GPUs, that’s a fact. Then, why are we using the CPU? well, there are a few reasons behind this decision:
- Complexity: Kernel programming is really hard and it gets even harder when we moved to specialized hardware like GPUs. We will have a easier time (not easy but easier) on the CPU to learn about the problem and the approach to optimizing it.
- Power usage: GPUs are in general really power hungry, the CPU is less power hungry and used in some low power scenarios (although there are low power GPUs and ASICs too)
- Memory Bandwidth: In most cases AI is quite memory bound so more raw compute power (like having a GPU) won’t solve this issue. Having an external chip also means that the data must travel via PCIe from the CPU and back. That’s why CPUs are still used in some scenarios 1
Considerations before starting
I want this post to be as focused on kernel development as possible, that is why we won’t discuss things as measuring time or other aspects here, for those interested the code will be on my GitHub. We will follow a simple approach where we present a basic kernel and will keep expanding it and improving it without focusing on the main function of the code. As with almost all code that is HPC related in the CPU we will be using C which let’s us control really low level details.
Basic Kernel
The most basic kernel one can think of is usually one that looks like this:
void gemm(int M, int N, int K, float alpha, float *A, float *B, float beta, float *C)
{
if (beta != 1.0f)
{
for(int i = 0; i < M*N; i++)
C[i] *= beta;
}
for (int i = 0; i < M; i++)
{
for (int j = 0; j < N; j++)
{
for (int k = 0; k < K; k++)
{
C[i * N + j] += alpha * A[i * K + k] * B[k * N + j];
}
}
}
}
In here we are first, precomputing the beta scaling and then doing the matrix multiplication also adding alpha. The algorithm used here is inner product which just means we are taking a row of A and a column of B this is the way you were probably taught in your algebra class in high-school.
However, we could do it the opposite way, taking the columns of A and the rows of B, Does it matter?. Yes it does, here is where the first important concept regarding CPU architecture comes up and it’s caches.
By decreasing the cache fails we will get an speedup as every cache fail introduces a penalty of many cycles. Using an inner product approach (Columns of A, rows of B) helps reduce cache misses. To do that we just need to change the order of the loops to:
void gemm(int M, int N, int K, float alpha, float *A, float *B, float beta, float *C)
{
if (beta != 1.0f)
{
for(int i = 0; i < M*N; i++)
C[i] *= beta;
}
for (int i = 0; i < M; i++)
{
for (int k = 0; k < K; k++)
{
for (int j = 0; j < N; j++)
{
C[i * N + j] += alpha * A[i * K + k] * B[k * N + j];
}
}
}
}
Here making the j loop the innermost one means that we will take a single element of A and multiply it with a whole row of B, this way we will be accessing B in a more cache friendly way. However, now we will be calculating partial sums in C. Still, this way is more cache friendly for now.
The last thing we can do to conclude this section is a really simple improvement yet one that will give us good performance gains and it’s using all of our CPU cores (as now we are using just one). A simple way to do it is by using OpenMP, we just need to add a single pragma:
void gemm(int M, int N, int K, float alpha, float *A, float *B, float beta, float *C)
{
if (beta != 1.0f)
{
for(int i = 0; i < M*N; i++)
C[i] *= beta;
}
#pragma omp parallel for
for (int i = 0; i < M; i++)
{
for (int k = 0; k < K; k++)
{
for (int j = 0; j < N; j++)
{
C[i * N + j] += alpha * A[i * K + k] * B[k * N + j];
}
}
}
}
This pragma splits the work of every iteration in different treads (and thus in different cores). Here we are exploiting the fact that every element of C can be calculated independently, we call this Data Level Parallelism (or DLP) and that is why there are no race conditions here.
With this we can conclude a basic implementation that yields a performance of 167 GFlops on my CPU (Intel Core i9-10900) for reference state of the art libraries like OpenBLAS can reach up to 1 TFLop on my CPU so we still have lots of work to do.
Tiling
Tiling is one of the most important optimizations in general (not just for CPUs) its goal is to partition the matrix into smaller matrices so that smaller matrices fit into higher levels of memory in the case of the CPU on caches.
Since we will be computing sub-matrices we need to take into account that each step we will be calculating partial sums not the whole result at once. In terms of code we are splitting it into two functions, the first function is almost identical to the one we had earlier:
void ukernel(int M, int N, int K, int i_begin, int j_begin, int k_begin, int i_end, int j_end, int k_end, float alpha, float *A, float *B, float *C)
{
for (int i = i_begin; i < i_end; i++)
{
for (int k = k_begin; k < k_end; k++)
{
for (int j = j_begin; j < j_end; j++)
{
C[i * N + j] += alpha * A[i * K + k] * B[k * N + j];
}
}
}
}
But we are also setting the start and end of our sub-matrix so we don’t calculate the whole thing. Next we just need to call this function from another function that takes care of correctly partitioning the matrix:
#define min(a, b) (((a) < (b)) ? (a) : (b))
void gemm(int M, int N, int K, float alpha, float *A, float *B, float beta, float *C,
int tile_size_M, int tile_size_N, int tile_size_K)
{
if (beta != 1.0f)
{
for (int i = 0; i < M * N; i++)
C[i] *= beta;
}
#pragma omp parallel for collapse(2)
for (int i = 0; i < M; i += tile_size_M)
{
for (int j = 0; j < N; j += tile_size_N)
{
for (int k = 0; k < K; k += tile_size_K)
{
int i_end = min(i + tile_size_M, M);
int j_end = min(j + tile_size_N, N);
int k_end = min(k + tile_size_K, K);
ukernel(M, N, K, i, j, k, i_end, j_end, k_end, alpha, A, B, C);
}
}
}
}
Here we apply the beta scaling and do the needed arithmetic to make sure we partition the sub-matrices correctly, we now apply the OpenMP parallelization here (the collapse directive collapses both loops into one and parallelizes both).
There are also parameters that indicate the tile size, selecting an optimal or near optimal tile size is a crucial non-trivial task that could take another entire blog post. Mainly you need to make sure that with the sizes you select the matrices must fit on your different levels of cache but there is also a big part of experimenting with different sizes as caches are complex structures and theoretical calculations are not enough.
In this case I have just carried out some theoretical calculations so we can expect that the tile size selected is not the best but enough for this example. Taking into account the tile of A is of size M*K and the tile of B is of size K*N and I want my tile of A to fit on my L1 (320KB) and B on my L2 (2.5MB) I selected: M=32, N=1024, K=256. Using a big N, medium K and small M is usually a great approximation.
However, with this optimization we just got 165 GFlops so no improvement at all. Still tilling will be useful when we apply more optimization on top of it.
Vectorization with Intrinsics
Another important hardware part of the CPU are SIMD (Single Instruction Multiple Data) units, as the name implies this unit run a single instruction over a vector of data for example let’s say you have a two vectors V and U and you want to add the components of both. Here is a silly example:
V = {1 2 3 4 5 6 7 8}
U = {8 7 6 5 4 3 2 1}
W = U + V = {9 9 9 9 9 9 9 9}
Here V and U are vectors of size 8 if we interpret each number as a 32-bit value we have 256 bits for each vector. Now imagine you had registers of 256 bits in your CPU and functional units capable of using them, well turns out you do!.
Those are the SIMD units, implementations varies according to the architecture but for x86 CPUs you will mostly find AVX2 and on ARM chips you might find NEON (or newer SVE) but both work similarly. With AVX2 we now have 256 bit registers and assembly operations that can operate on them, that means we can populate those registers with 8 32-bit elements 16 16-bit elements or any combination supported by the hardware and a single instruction will operate over all of the data (SIMD).
If you are interested SIMD can get better and more complex that just AVX, there are vector processor which were the main supercomputers back in the 80’s and the philosophy behind it still applies to ARM SVE and SME and into the RISC-V vector extensions. However in our case we will just stick with AVX.
In our GEMM code there is a clear point where we are operating with vectors and it’s on the accumulation:
C[i * N + j] += alpha * A[i * K + k] * B[k * N + j];
There we are taking an element of A and multiplying it over a vector of B, the compiler is probably translating this to AVX instructions already but by doing it manually we can ensure it is done in a more efficient way. For that we will need intrinsics which are just special low level instructions that map directly to assembly. Here is how our ukernel would look like now (tiling stays the same):
inline void ukernel(int M, int N, int K, int i_begin, int j_begin, int k_begin, int i_end, int j_end, int k_end, float alpha, float *A, float *B, float *C)
{
for (int i = i_begin; i < i_end; i++)
{
int j = j_begin;
for (; j <= j_end-8; j += 8)
{
// Load 8 elements of C
__m256 c_vec = _mm256_loadu_ps(&C[i * N + j]);
for (int k = k_begin; k < k_end; k++)
{
// Broadcast a single A element into a vector register
__m256 a_broadcast = _mm256_set1_ps(A[i * K + k] * alpha);
// Load 8 elements of B
__m256 b_vec = _mm256_loadu_ps(&B[k * N + j]);
// FMA
c_vec = _mm256_fmadd_ps(a_broadcast, b_vec, c_vec);
}
// Write to memory
_mm256_storeu_ps(&C[i * N + j], c_vec);
}
// Remainder loop.
for (; j < j_end; j++)
{
for (int k = k_begin; k < k_end; k++)
{
C[i * N + j] += alpha * A[i * K + k] * B[k * N + j];
}
}
}
}
As you can see we are not using __m256 datatype that represent those 256 bit registers we spoke about, thats also why the j loop now increments 8 by 8. In the accumulation we use the fmadd instructions which just means Fused Multiply Add and its a special instruction that performs a multiplication and addition at the same time plus it is also a vector instruction.
An iteration of how this would work can be seen here (assuming vector of 4 elements for simplicity):
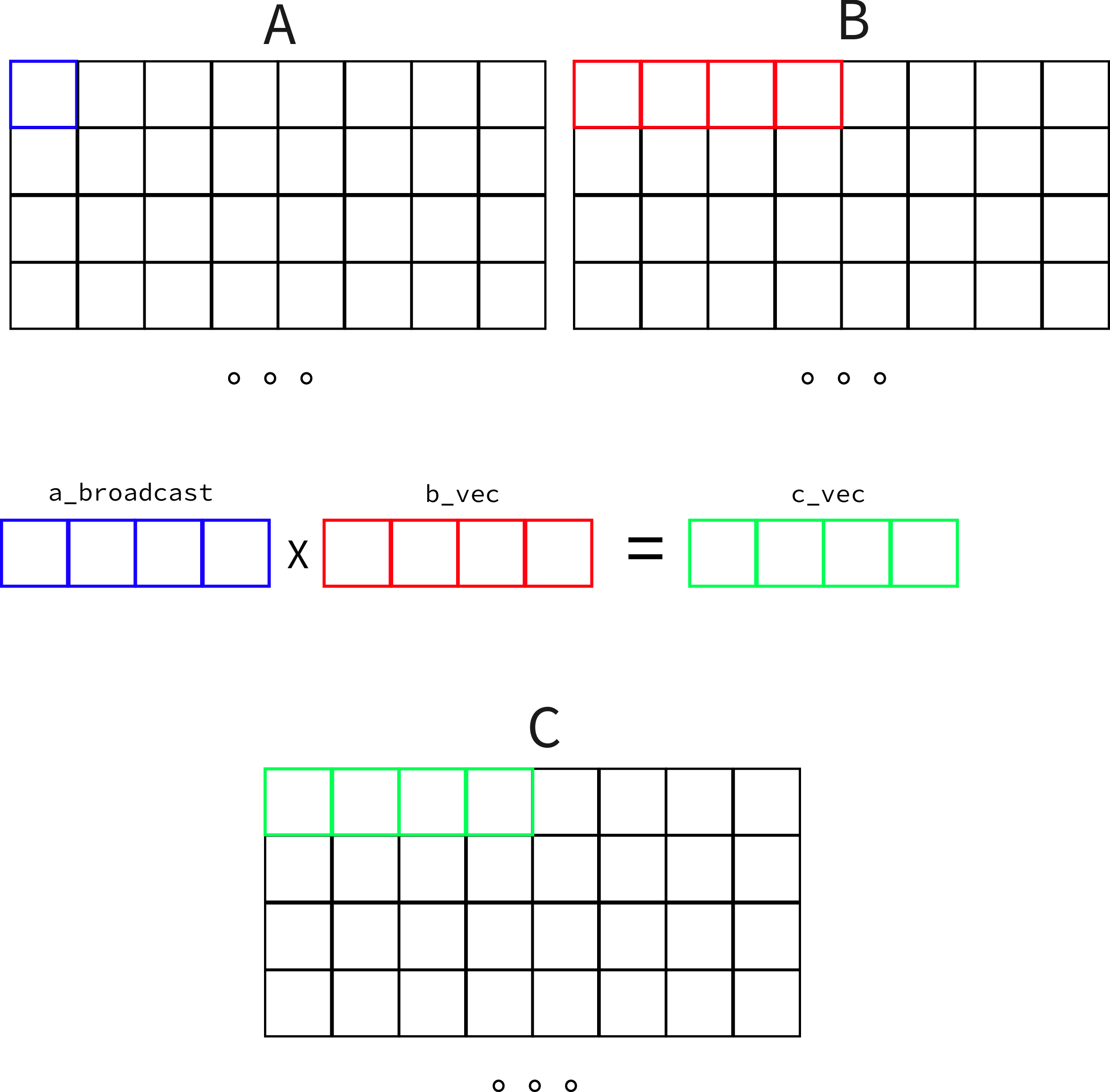
With this implementation we get… 136 GFLops, you might be starting to think that this is quite dumb as we are each step of the way introducing complexity and worsening the performance but this has an easy explanation and I promise you next time we will surely get a speed-up.
The reason why this code performs worse is because now that we are using intrinsics, the compiler cannot optimize as much as we have taken part of his work and it did a better job than us (for now). But next I will show you a simple and key optimization that will get us a great speedup.
Loop Unrolling
One of the optimizations the compiler normally carries out is Loop Unrolling, this just means using bigger “steps” on a loop for example if you write something like this:
for(int i = 0; i < N; i++){
do_something(i);
}
The compiler might unroll it to something like this:
for(int i = 0; i < N; i+=4){
do_something(i+0);
do_something(i+1);
do_something(i+2);
do_something(i+3);
}
This is to avoid loop overhead since every time we do a new iteration a jump instruction happens to go to the start of the loop again adding some overhead. On top of that we also squeeze more performance of the functional units with this as if we have more than one functional unit we can run several operations in parallel. That is why this optimization is key, this is how this optimization looks on our GEMM code:
inline void ukernel(int M, int N, int K, int i_begin, int j_begin, int k_begin, int i_end, int j_end, int k_end, float alpha, float *A, float *B, float *C)
{
int i = i_begin;
for (; i <= i_end - 4; i += 4)
{
int j = j_begin;
for (; j <= j_end - 8; j += 8)
{
__m256 c0 = _mm256_loadu_ps(&C[(i + 0) * N + j]);
__m256 c1 = _mm256_loadu_ps(&C[(i + 1) * N + j]);
__m256 c2 = _mm256_loadu_ps(&C[(i + 2) * N + j]);
__m256 c3 = _mm256_loadu_ps(&C[(i + 3) * N + j]);
for (int k = k_begin; k < k_end; k++)
{
__m256 a0 = _mm256_set1_ps(A[(i + 0) * K + k] * alpha);
__m256 a1 = _mm256_set1_ps(A[(i + 1) * K + k] * alpha);
__m256 a2 = _mm256_set1_ps(A[(i + 2) * K + k] * alpha);
__m256 a3 = _mm256_set1_ps(A[(i + 3) * K + k] * alpha);
__m256 b_vec = _mm256_loadu_ps(&B[k * N + j]);
c0 = _mm256_fmadd_ps(a0, b_vec, c0);
c1 = _mm256_fmadd_ps(a1, b_vec, c1);
c2 = _mm256_fmadd_ps(a2, b_vec, c2);
c3 = _mm256_fmadd_ps(a3, b_vec, c3);
}
_mm256_storeu_ps(&C[(i + 0) * N + j], c0);
_mm256_storeu_ps(&C[(i + 1) * N + j], c1);
_mm256_storeu_ps(&C[(i + 2) * N + j], c2);
_mm256_storeu_ps(&C[(i + 3) * N + j], c3);
}
// Remainder
for (; j < j_end; j++)
{
for (int k = k_begin; k < k_end; k++)
{
C[(i+0) * N + j] += alpha * A[(i+0) * K + k] * B[k * N + j];
C[(i+1) * N + j] += alpha * A[(i+1) * K + k] * B[k * N + j];
C[(i+2) * N + j] += alpha * A[(i+2) * K + k] * B[k * N + j];
C[(i+3) * N + j] += alpha * A[(i+3) * K + k] * B[k * N + j];
}
}
}
// Remainder loop
for (; i < i_end; i++)
{
int j = j_begin;
for (; j <= j_end - 8; j += 8)
{
__m256 c_vec = _mm256_loadu_ps(&C[i * N + j]);
for (int k = k_begin; k < k_end; k++)
{
__m256 a_broadcast = _mm256_set1_ps(A[i * K + k] * alpha);
__m256 b_vec = _mm256_loadu_ps(&B[k * N + j]);
c_vec = _mm256_fmadd_ps(a_broadcast, b_vec, c_vec);
}
_mm256_storeu_ps(&C[i * N + j], c_vec);
}
// Remainder loop
for (; j < j_end; j++)
{
for (int k = k_begin; k < k_end; k++)
{
C[i * N + j] += alpha * A[i * K + k] * B[k * N + j];
}
}
}
}
As seen here the only thing we did is unroll the i loop by four, we also had to add the proper logic to handle sizes that are not multiples of four. With this we finally get a small improvement and manage to get 289 GFlops.
More aggressive unrolling.
We can increase the unrolling, this is not just an arbitrary decision, it’s based on the fact that AVX2 brings 16 vector registers and our goal is to use them all so increasing the unrolling from 4 to 8 can help. On top of that we can also optimize our algorithm a bit as we can take the computation of alpha out of the loop as we now have $$\sum(\alpha A B)$$ which is equal to $$\alpha \sum(AB)$$. The code now looks like this:
inline void ukernel(int M, int N, int K, int i_begin, int j_begin, int k_begin, int i_end, int j_end, int k_end, float alpha, float *A, float *B, float *C)
{
int i = i_begin;
for (; i <= i_end - 8; i += 8)
{
int j = j_begin;
for (; j <= j_end - 8; j += 8)
{
__m256 c0 = _mm256_setzero_ps();
__m256 c1 = _mm256_setzero_ps();
__m256 c2 = _mm256_setzero_ps();
__m256 c3 = _mm256_setzero_ps();
__m256 c4 = _mm256_setzero_ps();
__m256 c5 = _mm256_setzero_ps();
__m256 c6 = _mm256_setzero_ps();
__m256 c7 = _mm256_setzero_ps();
for (int k = k_begin; k < k_end; k++)
{
__m256 a0 = _mm256_set1_ps(A[(i + 0) * K + k]);
__m256 a1 = _mm256_set1_ps(A[(i + 1) * K + k]);
__m256 a2 = _mm256_set1_ps(A[(i + 2) * K + k]);
__m256 a3 = _mm256_set1_ps(A[(i + 3) * K + k]);
__m256 a4 = _mm256_set1_ps(A[(i + 4) * K + k]);
__m256 a5 = _mm256_set1_ps(A[(i + 5) * K + k]);
__m256 a6 = _mm256_set1_ps(A[(i + 6) * K + k]);
__m256 a7 = _mm256_set1_ps(A[(i + 7) * K + k]);
__m256 b_vec = _mm256_loadu_ps(&B[k * N + j]);
c0 = _mm256_fmadd_ps(a0, b_vec, c0);
c1 = _mm256_fmadd_ps(a1, b_vec, c1);
c2 = _mm256_fmadd_ps(a2, b_vec, c2);
c3 = _mm256_fmadd_ps(a3, b_vec, c3);
c4 = _mm256_fmadd_ps(a4, b_vec, c4);
c5 = _mm256_fmadd_ps(a5, b_vec, c5);
c6 = _mm256_fmadd_ps(a6, b_vec, c6);
c7 = _mm256_fmadd_ps(a7, b_vec, c7);
}
__m256 alpha_vec = _mm256_set1_ps(alpha);
__m256 C0 = _mm256_loadu_ps(&C[(i + 0) * N + j]);
__m256 C1 = _mm256_loadu_ps(&C[(i + 1) * N + j]);
__m256 C2 = _mm256_loadu_ps(&C[(i + 2) * N + j]);
__m256 C3 = _mm256_loadu_ps(&C[(i + 3) * N + j]);
__m256 C4 = _mm256_loadu_ps(&C[(i + 4) * N + j]);
__m256 C5 = _mm256_loadu_ps(&C[(i + 5) * N + j]);
__m256 C6 = _mm256_loadu_ps(&C[(i + 6) * N + j]);
__m256 C7 = _mm256_loadu_ps(&C[(i + 7) * N + j]);
C0 = _mm256_fmadd_ps(c0, alpha_vec, C0);
C1 = _mm256_fmadd_ps(c1, alpha_vec, C1);
C2 = _mm256_fmadd_ps(c2, alpha_vec, C2);
C3 = _mm256_fmadd_ps(c3, alpha_vec, C3);
C4 = _mm256_fmadd_ps(c4, alpha_vec, C4);
C5 = _mm256_fmadd_ps(c5, alpha_vec, C5);
C6 = _mm256_fmadd_ps(c6, alpha_vec, C6);
C7 = _mm256_fmadd_ps(c7, alpha_vec, C7);
_mm256_storeu_ps(&C[(i + 0) * N + j], C0);
_mm256_storeu_ps(&C[(i + 1) * N + j], C1);
_mm256_storeu_ps(&C[(i + 2) * N + j], C2);
_mm256_storeu_ps(&C[(i + 3) * N + j], C3);
_mm256_storeu_ps(&C[(i + 4) * N + j], C4);
_mm256_storeu_ps(&C[(i + 5) * N + j], C5);
_mm256_storeu_ps(&C[(i + 6) * N + j], C6);
_mm256_storeu_ps(&C[(i + 7) * N + j], C7);
}
// Remainder
for (; j < j_end; j++)
{
for (int k = k_begin; k < k_end; k++)
{
C[(i+0) * N + j] += alpha * A[(i+0) * K + k] * B[k * N + j];
C[(i+1) * N + j] += alpha * A[(i+1) * K + k] * B[k * N + j];
C[(i+2) * N + j] += alpha * A[(i+2) * K + k] * B[k * N + j];
C[(i+3) * N + j] += alpha * A[(i+3) * K + k] * B[k * N + j];
C[(i+4) * N + j] += alpha * A[(i+4) * K + k] * B[k * N + j];
C[(i+5) * N + j] += alpha * A[(i+5) * K + k] * B[k * N + j];
C[(i+6) * N + j] += alpha * A[(i+6) * K + k] * B[k * N + j];
C[(i+7) * N + j] += alpha * A[(i+7) * K + k] * B[k * N + j];
}
}
}
// Remainder
for (; i < i_end; i++)
{
int j = j_begin;
for (; j <= j_end - 8; j += 8)
{
__m256 c_vec = _mm256_loadu_ps(&C[i * N + j]);
for (int k = k_begin; k < k_end; k++)
{
__m256 a_broadcast = _mm256_set1_ps(A[i * K + k] * alpha);
__m256 b_vec = _mm256_loadu_ps(&B[k * N + j]);
c_vec = _mm256_fmadd_ps(a_broadcast, b_vec, c_vec);
}
_mm256_storeu_ps(&C[i * N + j], c_vec);
}
//Remainder
for (; j < j_end; j++)
{
for (int k = k_begin; k < k_end; k++)
{
C[i * N + j] += alpha * A[i * K + k] * B[k * N + j];
}
}
}
}
Packing
Packing is based on the idea of having fragments of A and B in a more friendly way arranged in memory. The goal for now is not having to access the memory using a big offset like we are doing with K and N. To do that we need a couple functions, one to pack A and one to pack B
void packA(float *A, int tile_size_M, int tile_size_K, int i_begin, int k_begin, int i_end, int k_end, int M, int K, float *packed_A)
{
for (int i = 0; i < tile_size_M; i++)
{
for (int k = 0; k < tile_size_K; k++)
{
int ii = i_begin + i;
int kk = k_begin + k;
if (ii < M && kk < K)
{
packed_A[i * tile_size_K + k] = A[(ii * K) + kk];
}
else
{
packed_A[i * tile_size_K + k] = 0.0f;
}
}
}
}
void packB(float *B, int tile_size_N, int tile_size_K, int j_begin, int k_begin, int j_end, int k_end, int K, int N, float *packed_B)
{
for (int k = 0; k < tile_size_K; k++)
{
for (int j = 0; j < tile_size_N; j++)
{
int kk = k_begin + k;
int jj = j_begin + j;
if (kk < K && jj < N)
{
packed_B[k * tile_size_N + j] = B[(kk * N) + jj];
}
else
{
packed_B[k * tile_size_N + j] = 0.0f;
}
}
}
}
The buffers where we are storing those pieces of A and B will be the same size of a tile for convenience. Now that all of our memory is contiguous we need to change the kernel to access the data correctly:
inline void ukernel(int lda, int ldb, int ldc, int i_end, int j_end, int k_end, float alpha, float *A, float *B, float *C)
{
int i = 0;
for (; i <= i_end - 8; i += 8)
{
int j = 0;
for (; j <= j_end - 8; j += 8)
{
// Load 8 elements of C for 8 rows
__m256 c0 = _mm256_setzero_ps();
__m256 c1 = _mm256_setzero_ps();
__m256 c2 = _mm256_setzero_ps();
__m256 c3 = _mm256_setzero_ps();
__m256 c4 = _mm256_setzero_ps();
__m256 c5 = _mm256_setzero_ps();
__m256 c6 = _mm256_setzero_ps();
__m256 c7 = _mm256_setzero_ps();
for (int k = 0; k < k_end; k++)
{
// Load A with broadcast (and mul alpha)
__m256 a0 = _mm256_set1_ps(A[(i + 0) * lda + k]);
__m256 a1 = _mm256_set1_ps(A[(i + 1) * lda + k]);
__m256 a2 = _mm256_set1_ps(A[(i + 2) * lda + k]);
__m256 a3 = _mm256_set1_ps(A[(i + 3) * lda + k]);
__m256 a4 = _mm256_set1_ps(A[(i + 4) * lda + k]);
__m256 a5 = _mm256_set1_ps(A[(i + 5) * lda + k]);
__m256 a6 = _mm256_set1_ps(A[(i + 6) * lda + k]);
__m256 a7 = _mm256_set1_ps(A[(i + 7) * lda + k]);
// Load 8 elements of B
__m256 b_vec = _mm256_loadu_ps(&B[k * ldb + j]);
// FMA
c0 = _mm256_fmadd_ps(a0, b_vec, c0);
c1 = _mm256_fmadd_ps(a1, b_vec, c1);
c2 = _mm256_fmadd_ps(a2, b_vec, c2);
c3 = _mm256_fmadd_ps(a3, b_vec, c3);
c4 = _mm256_fmadd_ps(a4, b_vec, c4);
c5 = _mm256_fmadd_ps(a5, b_vec, c5);
c6 = _mm256_fmadd_ps(a6, b_vec, c6);
c7 = _mm256_fmadd_ps(a7, b_vec, c7);
}
__m256 alpha_vec = _mm256_set1_ps(alpha);
__m256 C0 = _mm256_loadu_ps(&C[(i + 0) * ldc + j]);
__m256 C1 = _mm256_loadu_ps(&C[(i + 1) * ldc + j]);
__m256 C2 = _mm256_loadu_ps(&C[(i + 2) * ldc + j]);
__m256 C3 = _mm256_loadu_ps(&C[(i + 3) * ldc + j]);
__m256 C4 = _mm256_loadu_ps(&C[(i + 4) * ldc + j]);
__m256 C5 = _mm256_loadu_ps(&C[(i + 5) * ldc + j]);
__m256 C6 = _mm256_loadu_ps(&C[(i + 6) * ldc + j]);
__m256 C7 = _mm256_loadu_ps(&C[(i + 7) * ldc + j]);
C0 = _mm256_fmadd_ps(c0, alpha_vec, C0);
C1 = _mm256_fmadd_ps(c1, alpha_vec, C1);
C2 = _mm256_fmadd_ps(c2, alpha_vec, C2);
C3 = _mm256_fmadd_ps(c3, alpha_vec, C3);
C4 = _mm256_fmadd_ps(c4, alpha_vec, C4);
C5 = _mm256_fmadd_ps(c5, alpha_vec, C5);
C6 = _mm256_fmadd_ps(c6, alpha_vec, C6);
C7 = _mm256_fmadd_ps(c7, alpha_vec, C7);
// Write
_mm256_storeu_ps(&C[(i + 0) * ldc + j], C0);
_mm256_storeu_ps(&C[(i + 1) * ldc + j], C1);
_mm256_storeu_ps(&C[(i + 2) * ldc + j], C2);
_mm256_storeu_ps(&C[(i + 3) * ldc + j], C3);
_mm256_storeu_ps(&C[(i + 4) * ldc + j], C4);
_mm256_storeu_ps(&C[(i + 5) * ldc + j], C5);
_mm256_storeu_ps(&C[(i + 6) * ldc + j], C6);
_mm256_storeu_ps(&C[(i + 7) * ldc + j], C7);
}
}
}
The code now is simpler as now we know the exact size we will be computing and there is no need for remainder loops. Lastly we need to pack our data before every kernel call:
void gemm(int M, int N, int K, float alpha, float *A, float *B, float beta, float *C,
int tile_size_M, int tile_size_N, int tile_size_K)
{
if (beta != 1.0f)
{
for (int i = 0; i < M * N; i++)
C[i] *= beta;
}
#pragma omp parallel
{
float *packed_A = (float *)malloc(sizeof(float) * tile_size_M * tile_size_K);
float *packed_B = (float *)malloc(sizeof(float) * tile_size_N * tile_size_K);
#pragma omp for collapse(2)
for (int i = 0; i < M; i += tile_size_M)
{
for (int j = 0; j < N; j += tile_size_N)
{
for (int k = 0; k < K; k += tile_size_K)
{
int i_end = min(i + tile_size_M, M);
int j_end = min(j + tile_size_N, N);
int k_end = min(k + tile_size_K, K);
packA(A, tile_size_M, tile_size_K, i, k, i_end, k_end, M, K, packed_A);
packB(B, tile_size_N, tile_size_K, j, k, j_end, k_end, K, N, packed_B);
ukernel(tile_size_K, tile_size_N, N, tile_size_M, tile_size_N, tile_size_K, alpha, packed_A, packed_B, &C[i * N + j]);
}
}
}
free(packed_A);
free(packed_B);
}
}
We allocate one buffer per thread so we can keep doing the work concurrently. Still the data is not perfectly contiguos as we are still using a leading dimension. The ideal thing would be to have the columns of A and the rows of B all contiguos in memory. Also we are packing redundantly as for example packing A only depends on i and k but for every iteration of j we are also packing it again. That makes this implementation worse with a result of 169 GFlops.
Improved Packing
Our packing in the past section is not the best. If we remember we are accessing one element of A column-wise and we are broadcasting that element which we are multiplying against a row of B. Our goal is to translate that layout into the packing. To visualize this idea we can look at the following image.
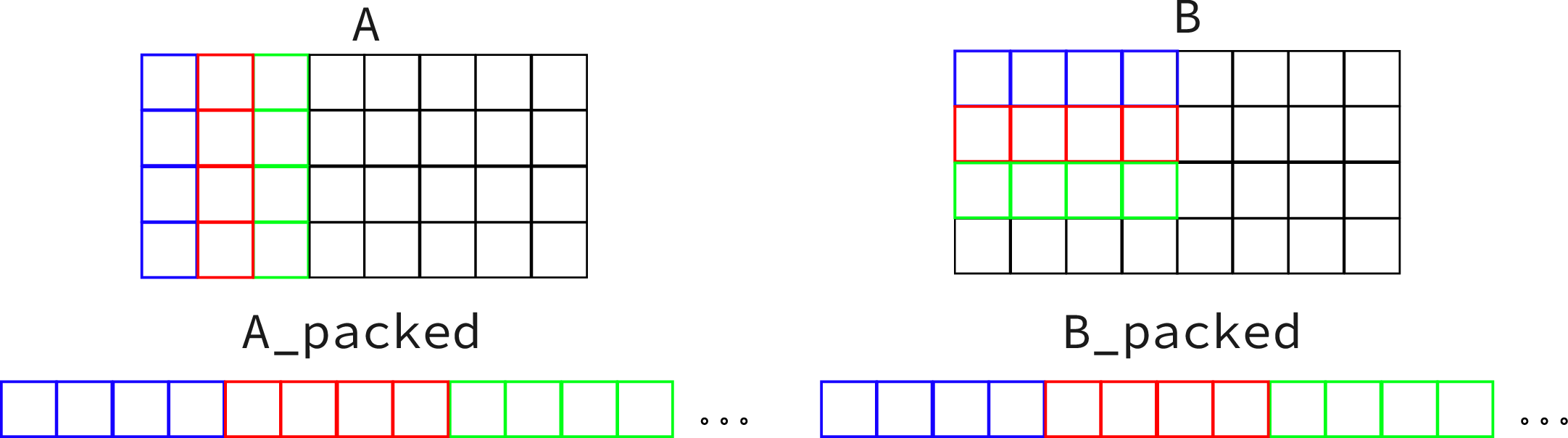
To accomplish this in the code we need to play with the indexing again:
void packA(float *A, int tile_size_M, int tile_size_K, int i_begin, int k_begin, int i_end, int k_end, int M, int K, float *packed_A)
{
int idx = 0;
for (int i = 0; i < tile_size_M; i += 8)
{
for (int k = 0; k < tile_size_K; k++)
{
for (int ii = 0; ii < 8; ii++)
{
int global_i = i_begin + i + ii;
int global_k = k_begin + k;
if (global_i < M && global_k < K)
{
packed_A[idx++] = A[(global_i * K) + global_k];
}
else
{
packed_A[idx++] = 0.0f;
}
}
}
}
}
void packB(float *B, int tile_size_N, int tile_size_K, int j_begin, int k_begin, int j_end, int k_end, int K, int N, float *packed_B)
{
int idx = 0;
for (int j = 0; j < tile_size_N; j += 8)
{
for (int k = 0; k < tile_size_K; k++)
{
for (int jj = 0; jj < 8; jj++)
{
int global_k = k_begin + k;
int global_j = j_begin + j + jj;
if (global_k < K && global_j < N)
{
packed_B[idx++] = B[(global_k * N) + global_j];
}
else
{
packed_B[idx++] = 0.0f;
}
}
}
}
}
Another optimization is changing the loop order to avoid unnecessary packing calls as mentioned before:
void gemm(int M, int N, int K, float alpha, float *A, float *B, float beta, float *C,
int tile_size_M, int tile_size_N, int tile_size_K, int padded_N)
{
if (beta != 1.0f)
{
for (int i = 0; i < M * padded_N; i++)
C[i] *= beta;
}
float *packed_B = (float *)malloc(sizeof(float) * tile_size_K * tile_size_N);
#pragma omp parallel
{
float *packed_A = (float *)malloc(sizeof(float) * tile_size_M * tile_size_K);
for (int j = 0; j < N; j += tile_size_N)
{
for (int k = 0; k < K; k += tile_size_K)
{
#pragma omp single
{
int j_end = min(j + tile_size_N, N);
int k_end = min(k + tile_size_K, K);
packB(B, tile_size_N, tile_size_K, j, k, j_end, k_end, K, N, packed_B);
}
#pragma omp for
for (int i = 0; i < M; i += tile_size_M)
{
int i_end = min(i + tile_size_M, M);
int k_end = min(k + tile_size_K, K);
packA(A, tile_size_M, tile_size_K, i, k, i_end, k_end, M, K, packed_A);
ukernel(tile_size_K, tile_size_N, padded_N, tile_size_M, tile_size_N, tile_size_K, alpha, packed_A, packed_B, &C[i * padded_N + j]);
}
}
}
free(packed_A);
}
free(packed_B);
}
The idea behind this is that B only depends on the j and k indices and A only depends on the k and i indices. With this new order we are just packing B when it is needed saving lots of calls. In the case of A we are still calling it more times than needed but there is no loop ordering that can benefit both A and B.
With this optimization we reach 487 GFLOPS.
Alignment and more Unrolling
One small but relevant detail we have not taken into account is that our buffers are perfectly aligned in memory (that is another reason why packing is useful). That let’s us use a slightly different intrinsic instead of using _mm256_loadu_psu we can use _mm256_loadu_ps (notice the missing U which means unaligned). On top of that we add some hints to the compiler so it knows memory is aligned and the intrinsics we use for memory allocating will also allocate aligned memory.
Lastly, I decided to unroll the innermost loop too and to add a pragma for vectorization in the packing function although it was probably getting vectorized automatically before. The whole code looks like this now:
__attribute__((always_inline)) inline void ukernel(int lda, int ldb, int ldc, int i_end, int j_end, int k_end, float alpha, float *restrict A, float *restrict B, float *restrict C)
{
A = (float *)__builtin_assume_aligned(A, 32);
B = (float *)__builtin_assume_aligned(B, 32);
int i = 0;
for (; i <= i_end - 8; i += 8)
{
int j = 0;
for (; j <= j_end - 8; j += 8)
{
// Load 8 elements of C for 8 rows
__m256 c0 = _mm256_setzero_ps();
__m256 c1 = _mm256_setzero_ps();
__m256 c2 = _mm256_setzero_ps();
__m256 c3 = _mm256_setzero_ps();
__m256 c4 = _mm256_setzero_ps();
__m256 c5 = _mm256_setzero_ps();
__m256 c6 = _mm256_setzero_ps();
__m256 c7 = _mm256_setzero_ps();
int k = 0;
for (; k <= k_end - 4; k += 4)
{
float *a_ptr_0 = &A[i * lda + k * 8];
float *b_ptr_0 = &B[j * lda + k * 8];
// Load 8 elements of B
__m256 b_vec_0 = _mm256_load_ps(b_ptr_0);
// FMA (acumulativo)
c0 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_0[0]), b_vec_0, c0);
c1 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_0[1]), b_vec_0, c1);
c2 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_0[2]), b_vec_0, c2);
c3 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_0[3]), b_vec_0, c3);
c4 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_0[4]), b_vec_0, c4);
c5 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_0[5]), b_vec_0, c5);
c6 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_0[6]), b_vec_0, c6);
c7 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_0[7]), b_vec_0, c7);
// --------------- k+1 ----------------
float *a_ptr_1 = &A[i * lda + (k + 1) * 8];
float *b_ptr_1 = &B[j * lda + (k + 1) * 8];
// Load 8 elements of B
__m256 b_vec_1 = _mm256_load_ps(b_ptr_1);
// FMA (acumulativo)
c0 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_1[0]), b_vec_1, c0);
c1 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_1[1]), b_vec_1, c1);
c2 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_1[2]), b_vec_1, c2);
c3 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_1[3]), b_vec_1, c3);
c4 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_1[4]), b_vec_1, c4);
c5 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_1[5]), b_vec_1, c5);
c6 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_1[6]), b_vec_1, c6);
c7 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_1[7]), b_vec_1, c7);
// --------------- k+2 ----------------
float *a_ptr_2 = &A[i * lda + (k + 2) * 8];
float *b_ptr_2 = &B[j * lda + (k + 2) * 8];
// Load 8 elements of B
__m256 b_vec_2 = _mm256_load_ps(b_ptr_2);
// FMA (acumulativo)
c0 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_2[0]), b_vec_2, c0);
c1 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_2[1]), b_vec_2, c1);
c2 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_2[2]), b_vec_2, c2);
c3 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_2[3]), b_vec_2, c3);
c4 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_2[4]), b_vec_2, c4);
c5 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_2[5]), b_vec_2, c5);
c6 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_2[6]), b_vec_2, c6);
c7 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_2[7]), b_vec_2, c7);
// --------------- k+3 ----------------
float *a_ptr_3 = &A[i * lda + (k + 3) * 8];
float *b_ptr_3 = &B[j * lda + (k + 3) * 8];
// Load 8 elements of B
__m256 b_vec_3 = _mm256_load_ps(b_ptr_3);
// FMA
c0 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_3[0]), b_vec_3, c0);
c1 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_3[1]), b_vec_3, c1);
c2 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_3[2]), b_vec_3, c2);
c3 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_3[3]), b_vec_3, c3);
c4 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_3[4]), b_vec_3, c4);
c5 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_3[5]), b_vec_3, c5);
c6 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_3[6]), b_vec_3, c6);
c7 = _mm256_fmadd_ps(_mm256_set1_ps(a_ptr_3[7]), b_vec_3, c7);
}
__m256 alpha_vec = _mm256_set1_ps(alpha);
__m256 C0 = _mm256_loadu_ps(&C[(i + 0) * ldc + j]);
__m256 C1 = _mm256_loadu_ps(&C[(i + 1) * ldc + j]);
__m256 C2 = _mm256_loadu_ps(&C[(i + 2) * ldc + j]);
__m256 C3 = _mm256_loadu_ps(&C[(i + 3) * ldc + j]);
__m256 C4 = _mm256_loadu_ps(&C[(i + 4) * ldc + j]);
__m256 C5 = _mm256_loadu_ps(&C[(i + 5) * ldc + j]);
__m256 C6 = _mm256_loadu_ps(&C[(i + 6) * ldc + j]);
__m256 C7 = _mm256_loadu_ps(&C[(i + 7) * ldc + j]);
C0 = _mm256_fmadd_ps(c0, alpha_vec, C0);
C1 = _mm256_fmadd_ps(c1, alpha_vec, C1);
C2 = _mm256_fmadd_ps(c2, alpha_vec, C2);
C3 = _mm256_fmadd_ps(c3, alpha_vec, C3);
C4 = _mm256_fmadd_ps(c4, alpha_vec, C4);
C5 = _mm256_fmadd_ps(c5, alpha_vec, C5);
C6 = _mm256_fmadd_ps(c6, alpha_vec, C6);
C7 = _mm256_fmadd_ps(c7, alpha_vec, C7);
// Write
_mm256_storeu_ps(&C[(i + 0) * ldc + j], C0);
_mm256_storeu_ps(&C[(i + 1) * ldc + j], C1);
_mm256_storeu_ps(&C[(i + 2) * ldc + j], C2);
_mm256_storeu_ps(&C[(i + 3) * ldc + j], C3);
_mm256_storeu_ps(&C[(i + 4) * ldc + j], C4);
_mm256_storeu_ps(&C[(i + 5) * ldc + j], C5);
_mm256_storeu_ps(&C[(i + 6) * ldc + j], C6);
_mm256_storeu_ps(&C[(i + 7) * ldc + j], C7);
}
}
}
#define min(a, b) (((a) < (b)) ? (a) : (b))
void packA(float *A, int tile_size_M, int tile_size_K, int i_begin, int k_begin, int i_end, int k_end, int M, int K, float *packed_A)
{
int idx = 0;
for (int i = 0; i < tile_size_M; i += 8)
{
for (int k = 0; k < tile_size_K; k++)
{
#pragma omp simd
for (int ii = 0; ii < 8; ii++)
{
int global_i = i_begin + i + ii;
int global_k = k_begin + k;
if (global_i < M && global_k < K)
{
packed_A[idx++] = A[(global_i * K) + global_k];
}
else
{
packed_A[idx++] = 0.0f;
}
}
}
}
}
void packB(float *B, int tile_size_N, int tile_size_K, int j_begin, int k_begin, int j_end, int k_end, int K, int N, float *packed_B)
{
int idx = 0;
for (int j = 0; j < tile_size_N; j += 8)
{
for (int k = 0; k < tile_size_K; k++)
{
#pragma omp simd
for (int jj = 0; jj < 8; jj++)
{
int global_k = k_begin + k;
int global_j = j_begin + j + jj;
if (global_k < K && global_j < N)
{
packed_B[idx++] = B[(global_k * N) + global_j];
}
else
{
packed_B[idx++] = 0.0f;
}
}
}
}
}
void gemm(int M, int N, int K, float alpha, float *A, float *B, float beta, float *C,
int tile_size_M, int tile_size_N, int tile_size_K, int padded_N)
{
if (beta != 1.0f)
{
for (int i = 0; i < M * padded_N; i++)
C[i] *= beta;
}
float *packed_B = (float *)_mm_malloc(sizeof(float) * tile_size_N * tile_size_K, 32);
#pragma omp parallel
{
float *packed_A = (float *)_mm_malloc(sizeof(float) * tile_size_M * tile_size_K, 32);
for (int j = 0; j < N; j += tile_size_N)
{
for (int k = 0; k < K; k += tile_size_K)
{
#pragma omp single
{
int j_end = min(j + tile_size_N, N);
int k_end = min(k + tile_size_K, K);
packB(B, tile_size_N, tile_size_K, j, k, j_end, k_end, K, N, packed_B);
}
#pragma omp for
for (int i = 0; i < M; i += tile_size_M)
{
int i_end = min(i + tile_size_M, M);
int k_end = min(k + tile_size_K, K);
packA(A, tile_size_M, tile_size_K, i, k, i_end, k_end, M, K, packed_A);
ukernel(tile_size_K, tile_size_N, padded_N, tile_size_M, tile_size_N, tile_size_K, alpha, packed_A, packed_B, &C[i * padded_N + j]);
}
}
}
_mm_free(packed_A);
}
_mm_free(packed_B);
}
With this little optimizations we are able to reach 586 GFLOPs.
Other relevant optimizations
There are many other optimizations to apply even in the context of CPU, GEMM is still a really complex operation. I would like to mention MMT4D which is the way the IREE compilers uses for GEMM 2. This approach uses a 4D approach where the two first dimensions are the tile index and the other two the element inside that tile, it also transposes B (That’s the meaning of the T on MMT4D).
Furthermore there are other optimizations that take into account the TLB which we completely ignore here a famous example is the GotoBLAS library (predecessor of OpenBLAS). This library was written by Kazushige Goto 3 and its a great example of a masterful implementation by someone who truly know the hardware well.
Performance comparison
Lastly we compare all of our implementations relatively to OpenBLAS for some sample sizes
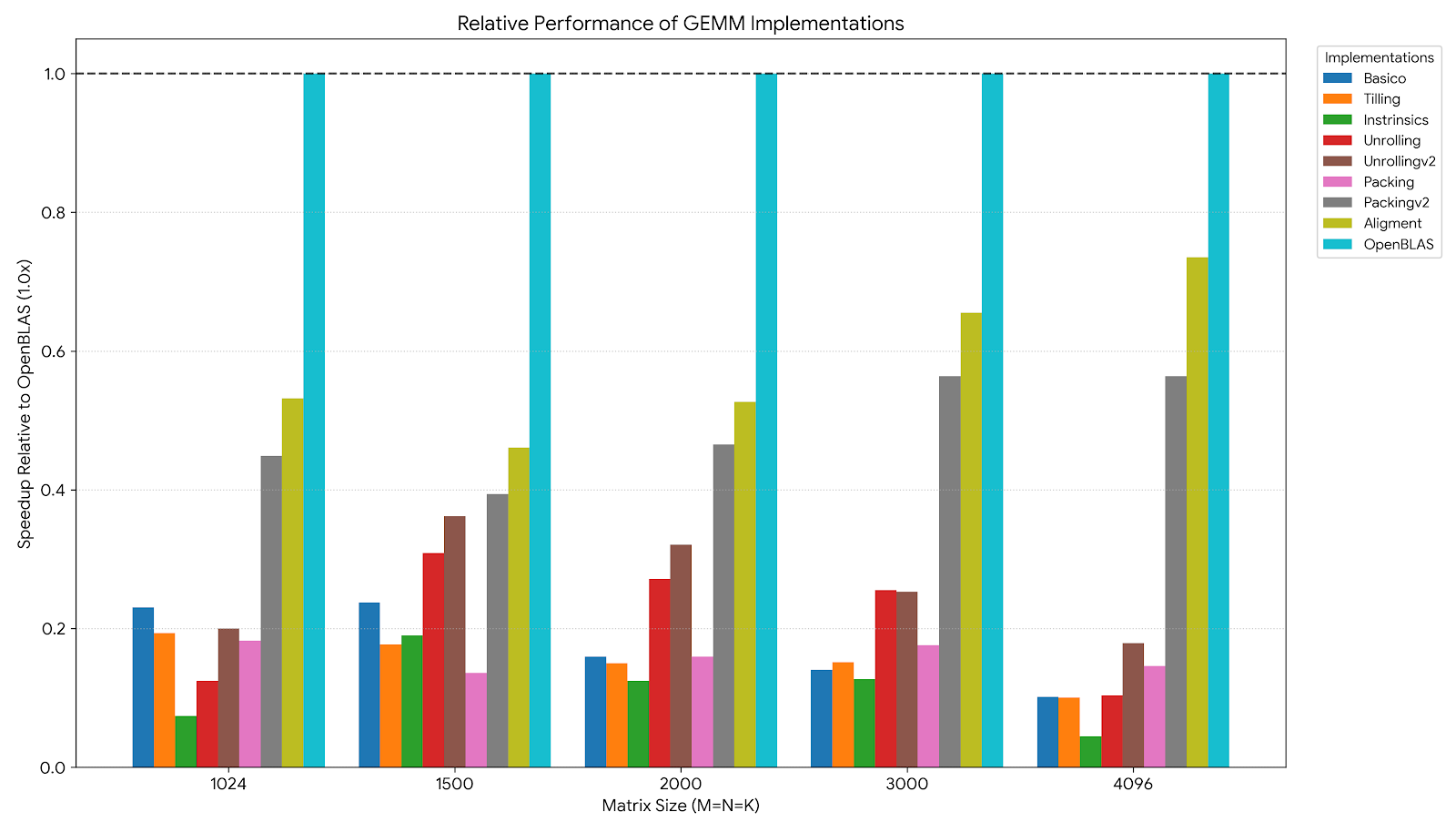
As seen in the image, on the best case we reach a 75% of the performance of OpenBLAS. We also observe how the bigger the size the more impact packing has.
OpenBLAS remains way superior as it is the standard library, compiled from source for my own CPU and written by the biggest experts in the world, likely some of the code in OpenBLAS was even written in assembly to get all of the performance out of the hardware. Framing it that way a 75% doesn’t sound that bad.
In conclusion we showed how hard truly the GEMM problem is even for a CPU which is simpler hardware than todays GPUs or ASICs. I hope you found this article helpful!. All the code is available here 4
Disclaimer: No AI was used to write the contents of this post, this is fully original and my own personal opinion.